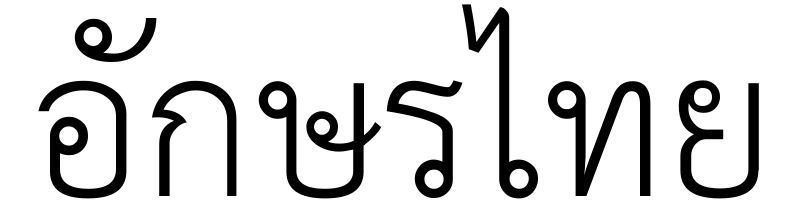
Thais alfabet
Also known as Thai, Thai alphabet
alfabet
AI overview
Thai script is a writing system used to write Thai, Southern Thai, and other languages spoken in Thailand, belonging to a category called an abugida where consonants and vowels are closely integrated. It matters as the essential tool for reading and writing in Thailand, enabling communication and literacy across the country.
AI-generated from the Wikipedia summary — may contain errors.
Wikidata facts
- Image
- Bangkok National Museum - 2017-04-22 (008).jpg
Sources (3)
via Wikidata · CC0
Article · Nederlands
Het Thaise schrift of het Thaise alfabet (Thai: อักษรไทย, àksǒn thai) wordt gebruikt om de Thaise taal en andere minderheidstalen in Thailand te schrijven. Het Thaise alfabet bestaat uit 44 medeklinkers (Thai: พยัญชนะ, phayanchaná). Hiernaast zijn er nog 15 klinkertekens waarmee ten minste 28 klinkers (Thai: สระ, sàrà) worden gevormd. Het schrift kent bovendien 4 toontekens (Thai: วรรณยุกต์, wannayúk), leestekens en tekens voor cijfers. Hoewel men spreekt van het "Thaise alfabet" is de tekenreeks in werkelijkheid geen echt alfabet maar een abugida uit de familie van Brahmische schriften. Een abugida is een schriftsysteem waarin de basisletters medeklinkers zijn met een impliciete klinker en consequente aanpassingen van de basisletters om andere klinkers aan te duiden. De medeklinkers worden horizontaal van links naar rechts geschreven. De klinkertekens worden boven, onder, links of rechts van de corresponderende medeklinker gepositioneerd, of in een combinatie van deze posities. Het Thaise schrift heeft eigen tekens voor de cijfers (Thai: ตัวเลขไทย, tua lek thai), maar de westerse cijfers (Thai: ตัวเลขฮินดูอารบิก, tua lek hindu arabik) worden ook vaak gebruikt. In een Thaise tekst zijn de woorden zonder spaties aan elkaar geschreven; een spatie vertegenwoordigt het einde van een zin of bijzin. Een tekst heeft, met uitzondering van een paar leestekens, weinig interpunctie. Behalve de Thaise leestekens worden soms leestekens van het Latijnse alfabet gebruikt, zoals ?, !, aanhalingstekens en haakjes. Het van buurland Laos lijkt veel op het Thaise schrift, maar heeft minder letters.
Abstract from DBpedia / Wikipedia · CC BY-SA